现在,ai已经能实时解读大脑信号了!
这不是耸人听闻,而是meta的一项新研究,能够凭脑信号猜出你在0.5秒内看的图,并用ai实时还原出来。
在此之前,ai虽然已经能从大脑信号中比较准确地还原图像,但还有个bug——不够快。
为此,meta研发了一个新解码模型,让ai光是图像检索的速度就提升了7倍,几乎“瞬间”能读出人在看什么,并猜出个大概。
像是一个站立的男人,ai数次还原后,竟然真的解读出了一个“站立的人”出来:
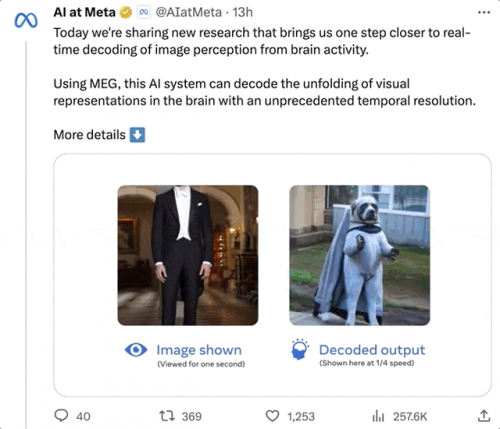
lecun转发表示,从meg脑信号中重建视觉等输入的研究,确实很棒。

那么,meta究竟是怎么让ai“快速读脑”的?
大脑活动解码如何解读?
目前,ai读取大脑信号并还原图像的方法,主要有两种。
其中一种是fmri(功能性磁共振成像),可以生成流向大脑特定部位的血流图像;另一种是meg(脑磁图),可以测量脑内神经电流发出的极其微弱的生物磁场信号。
然而,fmri神经成像的速度往往非常慢,平均2秒才出一张图(≈0.5 hz),相比之下meg甚至能在每秒内记录上千次大脑活动图像(≈5000 hz)。
所以相比fmri,为什么不用meg数据来试试还原出“人类看到的图像”呢?
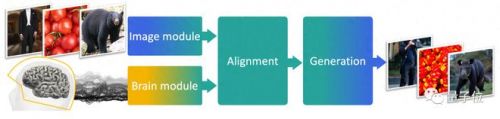
基于这一思路,作者们设计了一个meg解码模型,由三个部分组成。
第一部分预训练模型,负责从图像中获得embeddings;
第二部分是一个端到端训练模型,负责将meg数据与图像embeddings对齐;
第三部分是一个预训练图像生成器,负责还原出最终的图像。
训练上,研究人员用了一个名叫things-meg的数据集,包含了4个年轻人(2男2女,平均23.25岁)观看图像时记录的meg数据。
这些年轻人一共观看了22448张图像(1854种类型),每张图像显示时间为0.5秒,间隔时间为0.8~1.2秒,其中有200张图片被反复观看。
除此之外,还有3659张图像没有展示给参与者,但也被用于图像检索中。
所以,这样训练出来的ai,效果究竟如何?
图像检索速度提升7倍
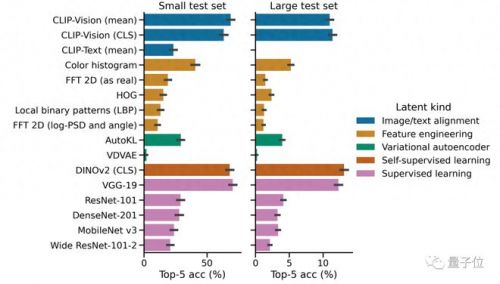
整体来看,这项研究设计的meg解码模型,比线性解码器的图像检索速度提升了7倍。
其中,相比clip等模型,又以meta研发的视觉transformer架构dinov2在提取图像特征方面表现更好,更能将meg数据和图像embeddings对齐起来。
作者们将整体生成的图像分成了三大类,匹配度最高的、中等的和匹配度最差的:

不过,从生成示例中来看,这个ai还原出来的图像效果,确实不算太好。
即使是还原度最高的图像,仍然受到了一些网友的质疑:为什么熊猫看起来完全不像熊猫?

作者表示:至少像黑白熊。(熊猫震怒!)
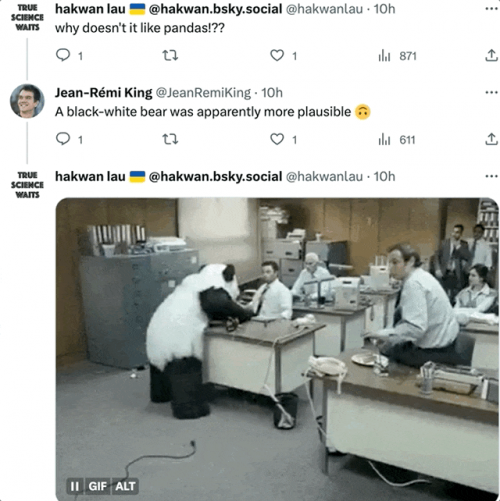
当然,研究人员也承认,meg数据复原出来的图像效果,确实目前还不太行,主要优势还是在速度上。
例如之前来自明尼苏达大学等机构的一项名为7t fmri的研究,就能以较高的复原度从fmri数据中还原出人眼看到的图像。

无论是人类的冲浪动作、飞机的形状、斑马的颜色、火车的背景,基于fmri数据训练的ai都能更好地将图像还原出来:
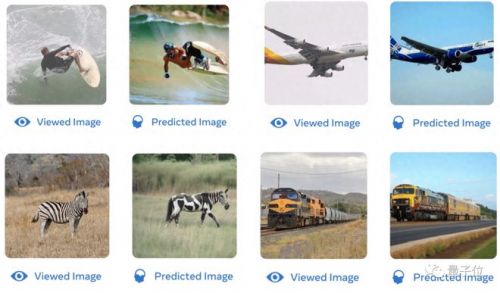
对此,作者们也给出了解释,认为这是因为ai基于meg还原出来的视觉特征偏高级。
但相比之下,7t fmri可以提取并还原出图像中更低级的视觉特征,这样生成的图像整体还原度更高。
你觉得这类研究可以被用在哪些地方?
https://ai.meta.com/static-resource/image-decoding