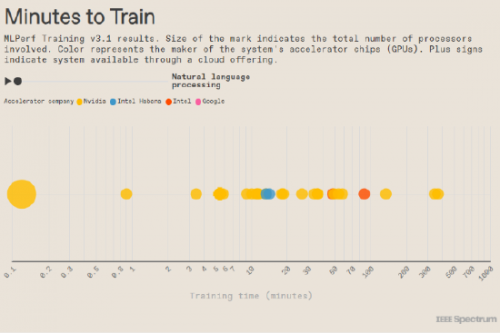
ai基准测试平台mlperf最新训练测试结果显示,英伟达处理器正遥遥领先,英特尔紧随其后,谷歌则远远落在了后面。针对计算机系统训练机器学习神经网络的公平测试(apples-to-applestest),已全面进入生成式人工智能时代。
今年年初,mlperf增加了一个用于训练大型语言模型(llm)的测试,主要是针对gpt-3。而就在本月,mlperf又增加了一个基于文本生成图像的测试stable diffusion。英伟达和英特尔的处理器参与了该基准测试,而在训练gpt-3时,谷歌也加入到了测试行列中。
ps:mlperf(machine learning performance)基准测试是由学术界和工业界共同组成的非营利性组织,旨在建立一个公平、透明且可复现的机器学习性能评估平台。该项目于2018年启动,得到了全球范围内众多知名学术机构和科技公司的支持与参与。其目标是为机器学习研究者和开发者提供一个统一的标准和基准测试工具,以促进机器学习系统的性能提升和相互比较。
三家公司都为这项任务投入了庞大的系统。其中,英伟达的10000gpu超级计算机是有史以来测试过的最大的超级计算机,而这种规模的超级计算机在生成式人工智能中是必不可少的。但即使这样,该计算机也需要八天的时间才能完全完成llm的训练任务。
本次测试共计有19家公司和机构提交了200多项测试结果,测试结果表明在过去五个月中计算机处理器性能提升了2.8倍,自五年前mlperf成立以来则提升了49倍。
10752个gpu的超级计算机
在mlperf基准测试中,英伟达公司的h100 gpu系统继续占据主导地位。但最令人惊喜的是该公司新推出的人工智能超级计算机eos,该计算机拥有高达10752个gpu。利用所有这些gpu完成gpt-3训练基准的任务,eos只用了不到4分钟时间。微软的云计算部门azure测试了一个大小完全相同的系统,结果却是仅以几秒之差落后于eos。(azure为github的编码助手copilot和openai的chatgpt提供训练支持)。
eos的gpu每秒可进行426亿亿次浮点运算(exaflops)。这些gpu与英伟达的quantum-2 infiniband互联,传输速度高达每秒110万亿字节。英伟达人工智能基准测试和云计算总监戴夫-萨尔瓦托雷说:“其速度和数据规模令人难以置信。这是一台能力惊人的机器。”

eos将单台机器上绑定的h100 gpu数量增加了三倍,这三倍的增长换来了2.8倍的性能提升,即93%的扩展效率。高效的扩展是持续改进生成式人工智能的关键,而生成式人工智能每年都在以10倍的速度增长。
eos所解决的gpt-3基准测试并不是对gpt-3的完整训练,因为mlperf希望大多公司都能做到这一点。相反,eos的任务是将系统训练到某个检查节点,以证明如果有足够时间的情况下,训练将能达到所需的准确度。
而这些训练确实需要时间。从以eos在这4分钟内的训练速度推算,完成所有训练需要8天,而这还是在迄今为止最强大的人工智能超级计算机上完成的。如果是一台普通的512 h100,则需要4个月时间。
英特尔步步紧逼
英特尔提交了使用gaudi 2加速芯片系统的测试结果,以及完全不使用加速芯片、仅使用第四代xeon cpu系统的测试结果。与上一组训练基准相比,最大的变化是英特尔启用了gaudi 2的8位浮点运算(fp8)功能。
过去10年中,gpu性能的提升主要归功于fp8等低精度数字的使用。在gpt-3和其他transformer神经网络中使用fp8,其低精度不会影响准确性,这已经在英伟达h100的测试结果中得到了验证。现在,在gaudi 2上也看到了这种提升。
英特尔habana实验室首席运营官艾坦-梅迪纳表示:“我们预计使用fp8会带来90%的提升。最终结果超出了预期——384加速器集群的训练时间缩短了103%”

这一新成果使gaudi 2系统的单芯片速度略低于英伟达系统的三分之一,是谷歌tpuv5e的三倍。而在新的图像生成基准测试中,gaudi 2的速度也只有h100的一半左右。gpt-3是本轮唯一启用fp8的基准测试,但梅迪纳说他的团队正在努力为其他基准测试启用fp8。
梅迪纳继续说明,gaudi 2的价格明显低于h100,因此在价格和性能的综合指标上具有优势。梅迪纳预计,随着下一代英特尔加速器芯片gaudi 3的问世,这一优势将进一步扩大。该芯片将于2024年量产,采用与英伟达h100相同的半导体制造工艺。
另外,英特尔还提交了仅基于cpu的系统结果。同样,几项基准测试的训练时间都在几分钟到几小时之间。
除了mlperf基准之外,英特尔还分享了一些数据,显示4节点xeon系统(包含amx矩阵引擎)可以在不到五分钟的时间内对图像生成器的稳定扩散进行微调。微调是将已经训练好的神经网络专门用于某项任务,例如,英伟达的芯片设计ai就是对现有大型语言模型nemo的微调。